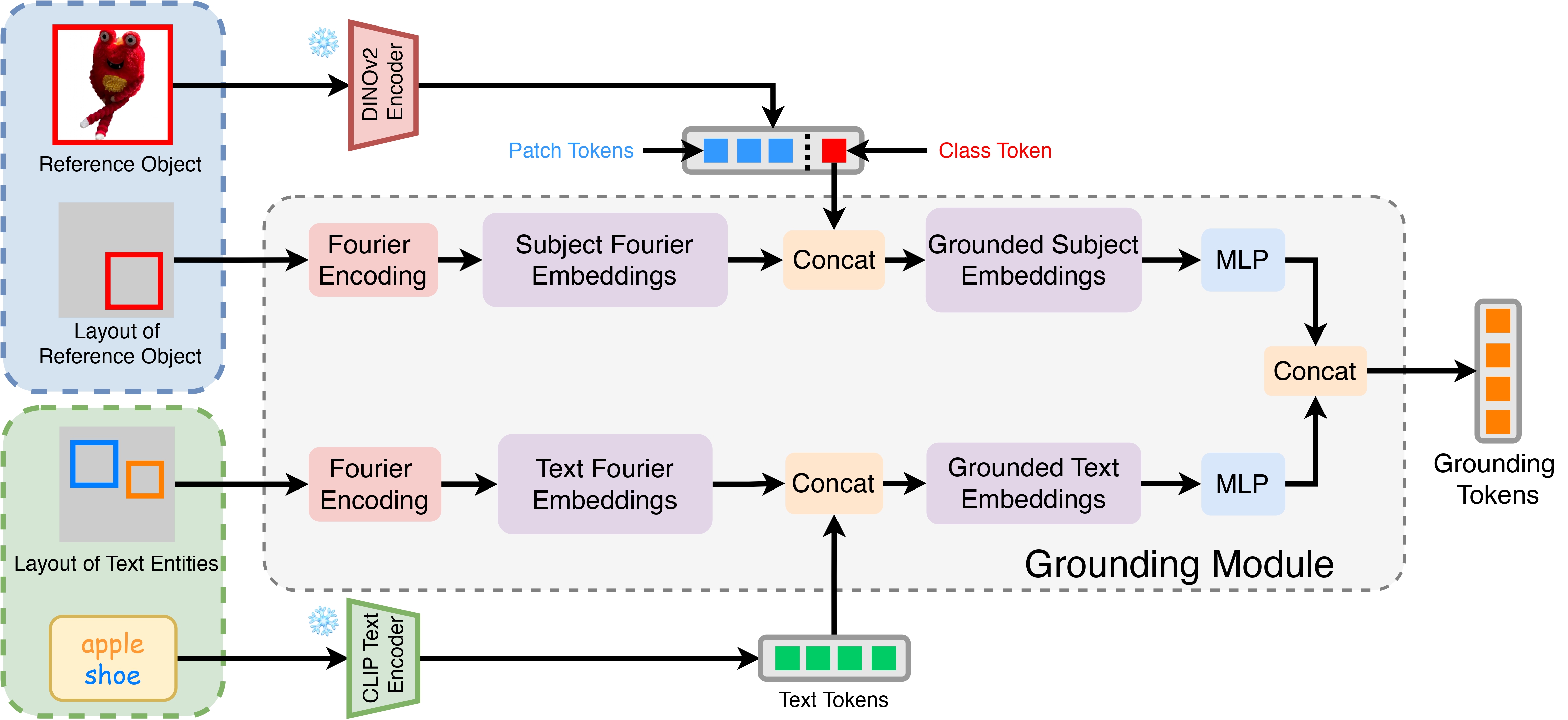
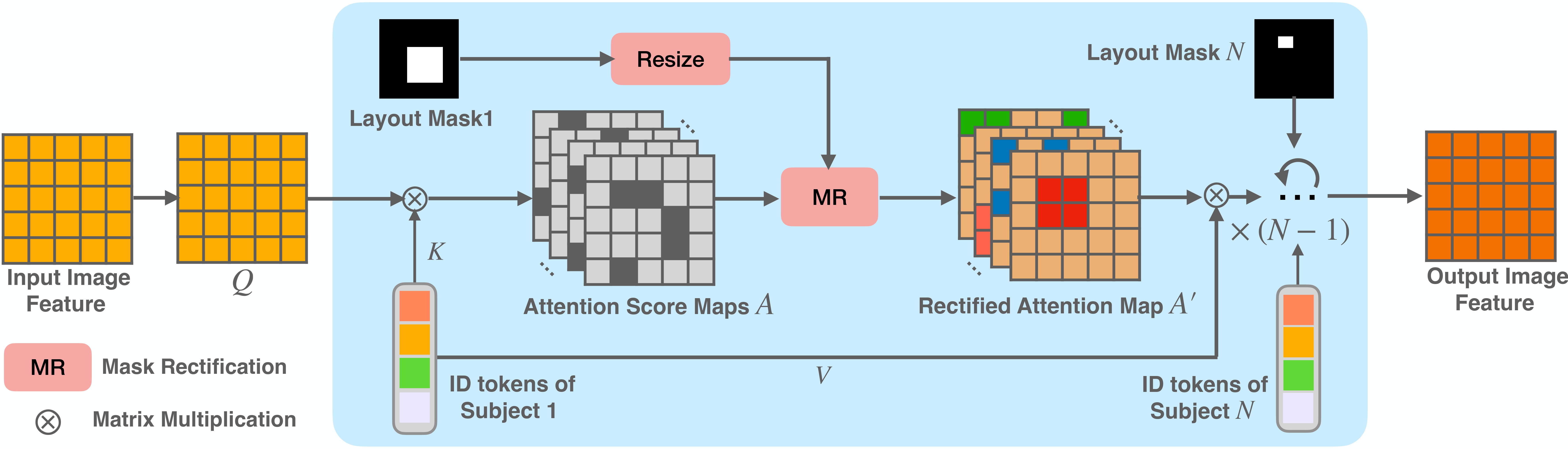
Recent approaches in text-to-image customization have primarily focused on preserving the identity of the input subject, but often fail to control the spatial location and size of objects. We introduce GroundingBooth, which achieves zero-shot, instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed grounding module and subject-grounded cross-attention layer enable the creation of personalized images with accurate layout alignment, identity preservation, and strong text-image coherence. In addition, our model seamlessly supports personalization with multiple subjects. Our model shows strong results in both layout-guided image synthesis and text-to-image customization tasks.
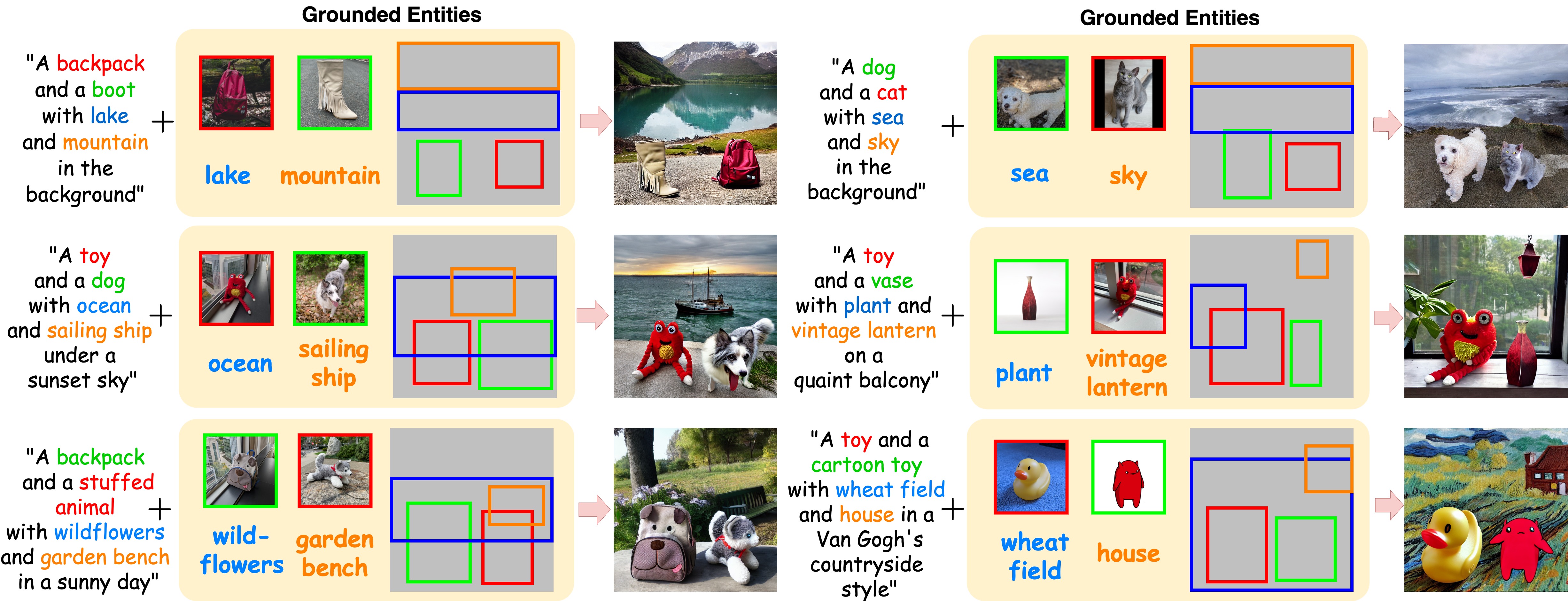

(a) grounded single-subject customization, and (b) joint grounded customization for multi-subjects and text entities. GroundingBooth achieves prompt following, layout grounding for both subjects and background objects, and identity preservation of subjects simultaneously.